Is Your Cloud Provider Keeping You Safe or Are You Just Getting Hosed


Storm of the Century... Perfect Storm... Catastrophic Event... All descriptions of hurricanes and other environmental occurrences that have hit us and left our communications vulnerable, right? Not exactly. To be sure, hurricanes, floods, earthquakes are a fact of life and occur every year and yet companies seem to be "caught off guard" and "are taken by surprise" every time. When that "caught off guard" company is delivering your mission critical business communications, well, that's something to talk about.
One of the benefits of moving your communications infrastructure to the cloud is the fact that you are no longer responsible for managing and maintaining that infrastructure, your cloud service provider is. They are supposed to be the experts and have the resources and experience to deliver your communications much more reliably than you could do on your own! While this might be true in theory, in the real world of catastrophic unforeseeable events, it is far from the truth and in many cases can severely impact your business to the point of damaging your reputation and potentially putting you out of business.
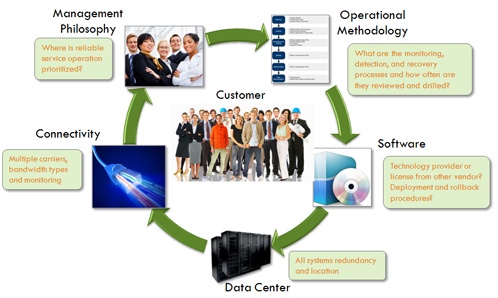
The problem comes down to the fact that there are a lot of moving parts to delivering a cloud service and not all cloud service providers have the real knowledge or experience to deliver the service in an ultra-reliable manner. As can be seen in the diagram below, there are 5 major components that impact the reliability and availability of cloud services:
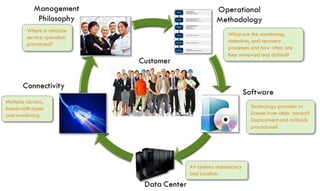
Let's start in the upper left corner with "Management Philosophy". You might ask "What, if anything, does Management Philosophy have to do with reliability and availability?" Well, a company focused solely on short term profits or quantity over quality might not spend the necessary time or money to make sure reliable operations are obtained and maintained. You see this every day in the retail business.... Nordstrom versus Walmart. Both are successful, but which one goes the extra mile for you? Corporate philosophy matters and when it comes to delivering your corporate communications, do you want Nordstrom or Walmart doing it?
Let's move on to "Operational Methodology." Wow, sounds like a grad school class! Well in some respects it is. Having sound processes, procedures and methods can mean the difference between an outage every month or every other year! It can also mean the difference between any particular outage lasting hours versus seconds or minutes. When you combine the worst case of frequency of outages and length of that outage, you can be down for a long long time. Pro-active monitoring, repetitive "fire drills" to remain prepared in case of an emergency, and clear, defined, written procedures and escalation paths are all keys to an operational methodology that minimizes both outage frequency and outage period. When the vendor receives a heads up of an impending disaster (like hurricane Sandy, which was reported on for days as being the worst storm to hit the east coast), are there procedures in place to pro-actively ensure a company’s full operation continues through the event? This might include moving users from one data center to another in a safer location. These are the kinds of preventive methodologies that separate an ultra-reliable cloud provider from the rest of the pack.
Let’s take a look at "Software." This is actually the WEAKEST LINK in the whole system, no matter which vendor you choose! Systems today are large and complex and contain thousands of lines of code. Invariably, new releases will fix old bugs, but introduce new ones. Is it hopeless? No, there are many things a vendor can and must do to reduce production bugs and minimize outages due to software. The most important thing is to "own" the software! A service provider that is also the technology provider and owns the software is able to directly test and QA the software and respond to bugs more quickly and with more accuracy than a service provider that licenses the technology from someone else. Owning the software can reduce outage times from hours down to minutes. Secondly, multi-level pre-testing at scale must be done to ensure most bugs are found and eliminated before reaching production. And thirdly, the software must be kept up to date. Running on old versions of software guarantees a higher probability of hitting a bug.
The "Data Center" is probably the attribute of their service most talked about by your vendor. They might say "we're fully redundant" and beat their chest as if that were the most important component to their reliability and availability. Unfortunately, they have missed the boat completely in even understanding reliability and availability. It has NOTHING to do with the most reliable component in the system, it has EVERYTHING to do with the LEAST reliable component in the system, which we have already identified as "Software." In fact, today, most vendor’s data centers are redundant such that any single hardware component failure is completely masked and doesn't impact reliability/availability at all. However, there is one important aspect to the data center even today: location! If the vendor’s data center is located in an area that is prone to natural disasters (like hurricanes and floods), then the vendor is asking for trouble and you are going to be the recipient of that trouble!
Finally, there is "Connectivity" which is actually the second weakest link right behind Software. While IP connectivity has gotten a lot better in the past couple of years, it still remains one of the highest failure rate items in cloud deployment. Again, a well-designed cloud deployment can mitigate many of the connectivity issues. Dual connections on different carriers with a load balancing router can reduce connectivity failures. Cloud vendors that proactively monitor carrier networks and can immediately switch upon detection of a carrier problem, will provide the most reliable operations.
So how is PanTerra different from other cloud vendors? Well, that's the $64,000 question. I'll give you the $1M answer in my next post.
.jpg?width=500&height=500&name=Are%20you%20Getting%20a%20Good%20Deal%20(1).jpg)
Comments